
Hola Amig@s,
Hace algún tiempo que no escribo en el blog. En esta ocasión os traigo un pequeño proyecto (más bien prueba de concepto) que se me ocurrió esta misma tarde, se trata de crear tu propio «Alexa» o «Siri» o también conocidos como Smart Speakers… pero con la particularidad de que utilizaremos la API de OpenAI para la obtención de las respuestas (a.k.a chatgpt) junto con un módulo ESP32 y micropython. A este proyecto le he llamado HERMES en honor al dios griego HERMES.
Hermes es el dios olímpico mensajero, de los viajeros y las fronteras, tanto físicas como del conocimiento, de los pastores, de los oradores y del ingenio, de los literatos y los poetas, del atletismo, de los pesos y las medidas, de los inventos y por su habilidad para la negociación. Google.
Lista de materiales
A continuación podréis encontrar un listado de los materiales necesarios para el proyecto. Tened en cuenta que los enlaces compartidos aquí pueden variar, y es recomendable pedir los componentes via AliExpress. Se utiliza Amazon solo como ejemplo.
Módulo ESP32, puede ser cualquiera, en mi caso utilizaré el esp-wroom-32 pero os vale cualquiera que sea ESP32. Ejemplo:
Módulo con micrófono incorporado, para este proyecto he utilizado el GY-MAX4466.
Amplificador con altavoces incluidos. Se vende un kit muy chulo en Amazon, de aquí podemos utilizar todo, excepto el módulo Bluetooth (aunque por BT podríamos también conectarnos al ESP32).
Amplificador stereo PAM8403
Pantalla Oled 1.3″ 128×64
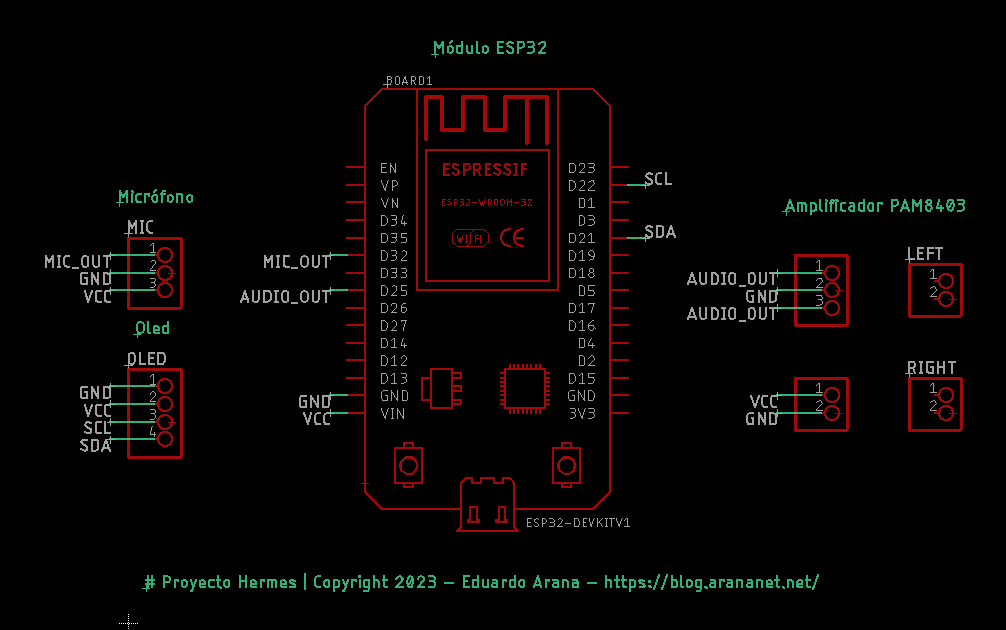
Diagrama de conexión
A continuación pueden encontrar un pequeño diagrama (utilizando EaglePCB) de las conexiones necesarias a nivel de hardware, utilizando los componentes mencionados anteriormente.
Código de ejemplo
El código detallado a continuación realizará las siguientes operaciones:
1-Convertirá la voz a texto.
2-El texto se pasará como payload a la API de OpenAI utilizando un modelo de datos específico, por ejemplo Text-Davinci-003.
3-La respuesta de la API se mostrará en una pantalla Oled.
4-La misma respuesta también se enviará a la API de Google Speech para obtener el text-to-voice de retorno, es decir para obtener el audio de la respuesta de la API de OpenAI. Recordad que, el código necesita personalizar ciertos parámetros, como puede ser la API key de OpenAI, la configuración de vuestra Wifi, etc. Mirad los comentarios en el código.
# Proyecto Hermes
# Copyright 2023 - Eduardo Arana - https://blog.arananet.net/
# Este código es una prueba de concepto.
# Requiere varias librerias y micropython para ESP32. Se recomienda el IDE VSCODE para implementar el código y desplegarlo directamente en el módulo ESP32.
import machine
import network
import urequests
import ujson
from time import sleep_ms
from ssd1306 import SSD1306_I2C
from machine import Pin, ADC, I2C, PWM
from umqtt.robust import MQTTClient
from speech2text import Speech2Text
from google_speech import Speech
# Definir los pines que se utilizarán para inicializar la pantalla OLED, el micrófono y altavoces
sda = Pin(21, Pin.IN, Pin.PULL_UP)
scl = Pin(22, Pin.IN, Pin.PULL_UP)
mic_pin = 32
speaker_pin = 25
# Configuramos el bus i2c para la pantalla OLED
i2c = I2C(sda=sda, scl=scl, freq=400000)
oled = SSD1306_I2C(128, 64, i2c)
# Conectando a la wifi local
sta_if = network.WLAN(network.STA_IF)
sta_if.active(True)
sta_if.connect('tu_wifi_ssid', 'tu_wifi_password')
while not sta_if.isconnected():
pass
print('Conectado a la Wi-Fi')
# Utilizamos un cliente MQTT para poder enviar la info a la API de OpenAI.
mqtt_client = MQTTClient(client_id='tu_client_id', server='mqtt.openai.org', port=8883, ssl=True, user='tu_usuario', password='tu_password')
# Inicializar los pines de ADC para poder leer el micrófono
mic = ADC(Pin(mic_pin))
mic.atten(ADC.ATTN_11DB) # configurarlo con una atenuación de 11dB.
# Configurar la salida PWM para reproducir el audio por los altavoces
speaker_pwm = PWM(Pin(speaker_pin))
speaker_pwm.duty(0)
# Definir función para convertir los valores del microfono a texto.
def convert_to_text():
speech2text = Speech2Text('tu_openai_api_key')
audio_data = []
for i in range(0, 4000):
audio_data.append(mic.read())
text = speech2text.transcribe(audio_data)
return text
# Definir función para sintetizar el texto a speech y reproducirlo por los altavoces. Forzamos a que la salida se diga en castellano pero puede personalizarse.
def speak(text):
speech = Speech(text, lang='es')
speech.play(speaker_pwm)
# Loop principal para capturar el comando o instrucción a enviar a la API de OpenAI API, y sintetizar la respuesta. De momento no hay control, está siempre escuchando y realizando la petición (cual espía encubierto) jajajaja.
while True:
oled.fill(0)
oled.text('Hablar ahora', 0, 0)
oled.show()
text = convert_to_text()
if text:
oled.fill(0)
oled.text(text, 0, 0)
oled.show()
data = {'text': text}
mqtt_client.connect()
mqtt_client.publish(topic='tu_tema', msg=ujson.dumps(data))
mqtt_client.disconnect()
response = urequests.post('https://api.openai.com/v1/chat', headers={'Content-Type': 'application/json', 'Authorization': 'Bearer your_openai_api_key'}, json={'model': 'text-davinci-003', 'prompt': text, 'temperature': 0.5, 'max_tokens': 50, 'stop': ['\n']})
response_text = ujson.loads(response.text)['choices'][0]['text'].strip()
oled.fill(0)
oled.text(response_text, 0, 0)
oled.show()
speak(response_text)
sleep_ms(1000)
Subiendo el código al módulo ESP32
Para subir el código al módulo ESP32 podemos hacerlo de dos formas diferentes, via el esptool que solo permite subir el firmware (bin) via USB o sino a través del despliegue via Visual Code. Para utilizar Visual Code, el enlace a continuación muestra un paso a paso completo para configurar el entorno de trabajo y desplegar los cambios directamente en el módulo.
Recordad que el tutorial anterior, cubre la mayoría de las configuraciones, una vez realizada configuración entre el ordenador y el módulo, podremos subir el código de ejemplo compartido en esta entrada.
Recuerden que esta es una idea o prueba de concepto de como podemos implementar una solución de consulta dinámica basada en el prompt via voz, y obteniendo un retorno coherente a la pregunta formulada. Obviamente este proyecto no interactúa con plataformas de música como Spotify, aunque sería plausible también, capturando ciertos comandos de voz y utilizando una serie de APIs para tal fin.
Espero que les haya gustado la idea. En cuanto tenga los componentes, haré un video de ejemplo.
Gracias por la visita.
Edu.